7.5. Evaluation
So how well did our hypotheses hold up? The experiment subsections above analyzed each demonstration individually. This section summarizes what that evidence supports when taken together. But first, let’s state the hypotheses again:
-
Robot-local execution with synchronized UI state, concurrent action layering, reactive tree logic, and behavior-time semantic perception yield door behaviors that are faster and more reliable than prior IHMC baselines and competitive with reported reinforcement learning systems on overlapping door tasks.
-
Runtime-editable behaviors and perception modules reduce the iteration loop required to diagnose failures, modify logic, and re-test on the robot, relative to redeploy, restart, or retrain workflows.
-
Decomposing behaviors into reusable primitives, subtrees, and scene actions allows new door and loco-manipulation variants to be brought up by editing a small part of a working behavior rather than rebuilding it from scratch.
Hypothesis 1 is supported on speed and capability, with partial and qualified support on reliability. Section 7.1 traced the arc from the 106 s Atlas hard coded anchor through 14 s and 27 s Nadia door traversals to 34 s and 45 s Alex traversals and the 2 minute 8 second two table sorting behavior. The 2021 Atlas door behavior took 3.9x longer to execute than our 2024 Nadia pull door behavior. Figure 7.29 placed those door results in the tens of seconds regime alongside Zhang et al. [56] and DoorMan [82], well below classical minute scale references.
Section 7.1 also documented 11/11 and 12/12 Alex door approach and opening repetitions, 32/32 Unitree standing door openings, and disturbed recoveries on doors and ball sorting (Figure 7.14). We did not repeat full door traversals, and we lack comparable repeat trial data for prior IHMC door baselines. Zhang et al. [56] show the most convincing reliability with their 20/20 and 18/20 trial sets for full door traversals. Learned systems such as Zhang et al. report higher trial counts on full traversals, so reliability comparisons should be read with that scope difference in mind. However, DoorMan [82] claims “83%” reliability, but does not share the data from which that number is calculated. We can say that the reliability of our system is competitive with learned door systems, especially when the resilience capabilities are factored in, which are also presented in Figure 7.14.
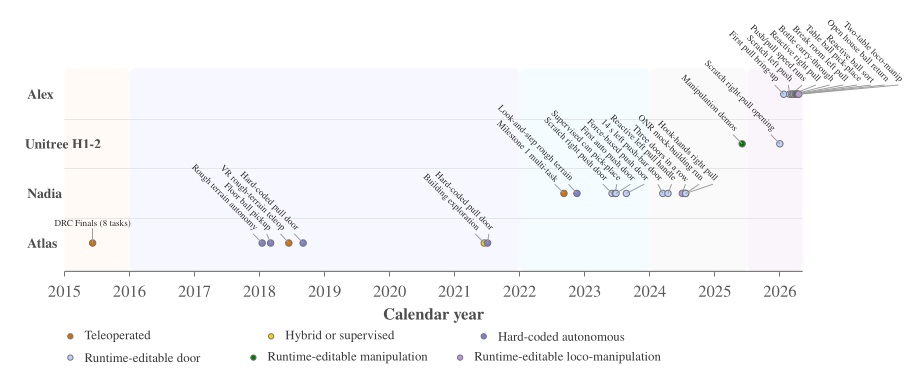
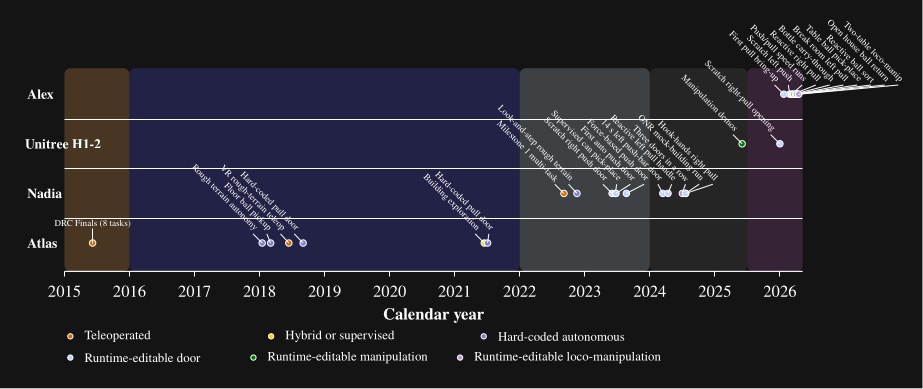
Hypothesis 2 is supported by the measured authoring sessions in Section 7.2. Runtime-editable behaviors and perception have reduced our behavior authoring times to the hours regime as shown in Figure 7.20. Scratch times ranged from 33 minutes for a partially autonomous Nadia session to about 11 hours for the first full Alex pull traversal, with a fully autonomous Alex left push door scratch authoring session at 1 hour 59 minutes 48 seconds. Creating new behaviors from scratch has been shown to require failure diagnostics, logic modification, and re-testing on the robot, which we have shown in our authoring videos and tables and described. While we don’t have direct comparisons with prior IHMC baselines, Figure 7.32 suggests a drastic reduction in the iteration loop required to create new behaviors. This figure spans a decade of IHMC real-robot behavior milestones from the 2015 DRC Finals through the Alex loco-manipulation demos in 2026. What we see is a drastic increase in the rate of new behavior demonstrations over time given the same or less resources allocated to creating them.
Hypothesis 3 is supported by the adaptation sessions in Section 7.3. A bottle-door carry composition session took 1 hour 13 minutes, lab to break room door adaptation took 1 hour 54 minutes, and the two table sorting extension took 1 hour 50 minutes including off robot pre-authoring. We credit our adaptation speed to our architectural decisions where we decompose behaviors into reusable primitives, subtrees, and scene actions. In each case, the work edited part of an existing behavior rather than rebuilding from an empty tree. The ability to perform these edits and re-test the behavior at runtime speeds up the process even further. Figure 7.31 estimates a 50 to 100 times speedup over DoorMan’s multi day pipeline for comparable create and adapt steps, but that literature comparison is inferred rather than directly measured. The literature does not provide data on the creation or modification timelines of loco-manipulation behaviors. Standing alone in measuring this is one of the most novel aspects of our work.
7.5.1. Desirable Characteristics
So how well did we achieve the desirable characteristics we defined in Desirable Characteristics? We think we did pretty well overall.
Our system is highly capable. We demonstrated dozens of different task varieties, from door traversal types and sorting objects on tables to building exploration. A taxonomy is illustrated in Figure 1.3. There are, however, classes of tasks we cannot do yet, such as grasping objects while the robot is walking, dynamic bracing, tasks that require proprioception, and fast manipulation tasks such as playing ping-pong. We cannot yet do them because the necessary control and perception components do not yet exist. Dancing, swimming, and sports are probably classes of tasks that this system is not well suited to address because they are too continuous, too dynamic, and even artistic.
Demonstrating our system was certainly feasible, as is shown by our results on real hardware. However, we did not show that it was feasible to take our system off-site and reproduce the results. Our system definitely supports fast behaviors, and we feel that the videos included of our real robot demonstrations are watchable at 1x speed. It also supports parallelism through moving multiple parts of the body at once, including being able to manipulate a door panel while walking.
We showed that our system is capable of producing reliable repeated-run behaviors for door approach and opening and for sorting balls on tables. Our walking controller was, however, not very reliable for the door traversal walk-throughs. We also showed how our system supports robustness to environmental disturbances through our pull door reactivity demo and our ball sorting demo with human disturbance. This goes hand in hand with our resilience capabilities. By using fallback nodes with condition nodes, common failure modes can be handled. For longer-tail resilience, we support this through operator-robot teaming. When behaviors fail, the human operator might be able to solve the problem with edits or additions to the behavior.
Our system is independent from external systems when it is in autonomous mode. It does not rely on external comms or compute in this mode, and our perception is entirely from on-board color vision.
Our system is designed around adaptability of the human-robot team. We have shown this through our results in behavior authoring. To achieve this, we made our system observable, predictable, and directable. Our system is learnable, and we have a handful of trained expert operators. We have provided a usage guide in Usage Guide. We hope the reader will find our system understandable through reading this thesis, watching the videos, and browsing the source code. We think the interface is easy to use, as suggested by our fast from-scratch authoring times.
Our system can be analyzed after behavior runs. We have done this via screen recordings of the operator interface and the log system shown in Section 4.6.9. It is also debuggable by looking at logged data and by rerunning behavior logic in an application we call the “behavior test facilitator”. This application uses a kinematic simulation combined with the playback of real perception data from a logged run. Very often, bugs can be reproduced and fixed in this environment. We also use this application to automate behavior tests.
Lastly, we view our system as being very extendable. As laid out in Building Our Behavior Architecture, the story of building it has been feature after brainstormed feature. This train of extension is still in active motion.
References cited on this page
[56] M. Zhang, Y. Ma, T. Miki, and M. Hutter, “Learning to open and traverse doors with a legged manipulator.” 2024. Available: https://arxiv.org/abs/2409.04882
[82] H. Xue et al., “Opening the sim-to-real door for humanoid pixel-to-action policy transfer,” arXiv preprint arXiv:2512.01061, 2025.